Recently there was in the news that champion Go player Lee Sedol was defeated by an AI. This was striking since experts were predicting that to get a computer play Go at the level computers played Chess was something to happen within 10 to 15 years.
How they did it and why was supposed to be such a difficult problem? They used an interesting trick. Existent technology used in an unconventional way.
But first lets talk about complexity. Let’s start with noughts and crosses puzzle. In game theory you can represent all stategies of a player in a form called extensive form. Or a tree. In this game players take turns. Same as in Chess and Go. So with every possible move you could create a tree where all boards are represented by nodes and edges are the possible moves. By making the computer take the moves where it wins it eventually always wins.
For noughts and crosses the number of possible boards is relativelly small. It has 9 moves so the tree has 9 levels and removing symmetries there are 138 game ends. This is quite easy to represent for a computer, even microcontrollers can deal with that. This is a game known to be perfectly solved. You will never defeat a computer playing it. All you can get is a draw.
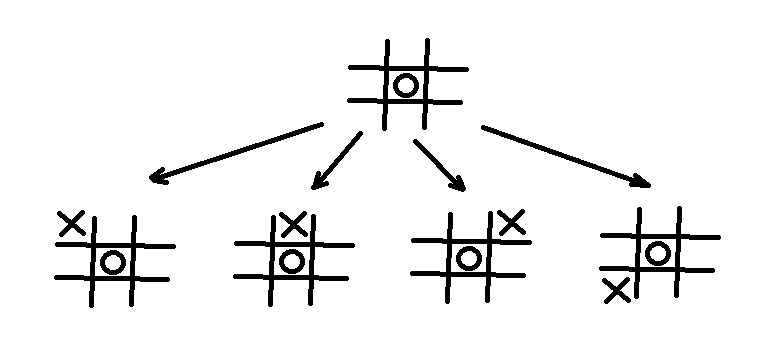
This is done with an algorithm called minimax. This algorithm’s main theorem was stated by french matematician Émile Borel and applies in game theory to zero sum games. Exactly it is is the largest value that the player can be sure to get without knowing the actions of the other players. Or in another way, the smallest value the other players can force the player to receive when they know his action. If you want more details please read the article.
For minimax 3 things are required:
- A way to generate the boards on each move.
- A way to evaluate the generated boards
- Pick the best next move
Now lets jump into chess. Chess is a game with a larger board, that is to represent each board consumes more memory. There are tricks to reduce the size but on average it weights more. But then each possible move in chess starts at 20 and the average game moves is 40-50 moves. This ends up being so large that no computer can properly deal with all possible board representations. Let alone the calculations to compute the boards.
It is not feasible to use that bruteforce like approach. So how computers defeat human players? Well thing is you don’t need all the boards for that. All you need is to evaluate enought forward steps taking the best moves and forget boards when things start to look bad for the player. This is called prunning.
What is this? Well it is based on the assumption that once a game is startig to look bad is simply better to not waste time working on something that likely is not going to get any better and assume it is a bad move. And since bad moves are usually the most common, this effectively reduces a load of processing time and memory that otherwise would be mostly wasted. But prunning brings a problem and is that it can potentially loose a good move that started to look bad but wasn’t actually a bad move and could have ended up in a victory. This is called the horizon problem. To overcome the horizon problem an algorithm called apha/beta prunning is used. However interesting as it is, its variations and optimizations, we are not going into the details, we’ll just leave the link. So with more than 18 plays ahead, specialized hardware in chess (chips that generate boards) and many processors (CPUs) Deep Blue supercomputer beated in 1997 the champion chess player then. By then Deep Blue used minimax but modern programs use prunning.
Now what is the problem with Go? Go is a very simple game to play, with very simple rules. There is a 19×19 board with black and white stones an players take turns to capture areas. But don’t be fooled by that simplicity. It is a far more complex game than chess for computers. Why? Three things:
- Average number of moves for Go is 250 possible moves
- The average moves in each game is more than 300 moves
- Not easy to evaluate how good or bad is a board for a player (champions can’t even describe exactly what makes them make a move)
How to solve this? Well something called Monte Carlo Tree Search is used sometimes when there is no idea on how to evaluate something or is too complex to calculate. For instance to calculate some integrals. Monte Carlo are a set of probabilistic experiments based in randomeness and statistics. And Monte Carlo Tree Search is a probabilistic search that converges to minimax with enought sampling (enought in this case is very high, assume infinite).
How it works? Basically, you take a board and pick a couple of random moves, and then just start playing to see how many makes you loose or win. And then with those numbers you can estimate how good or bad is the move with some certainty. The more evaluations of moves you perform the more it converges to minimax so anyone can selected how close or far they want it to be. Get the point where this is heading? Is not only the complexity of the board and moves, is also the complexity to evaluate the board! Not good. At least not to defeat a professional Go player in a limited time.
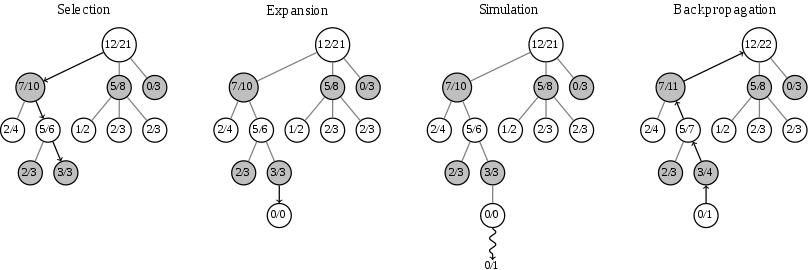
So how DeepMind engineers solved it in Alpha-go? Neural networks. A computer simulation of biological neural networks to be more precise. And the kind known as Deep Neural Networks. They are actually quite old and everywhere today but using them for this was the novel thing. So how they used neural networks there? Well neural networks can act as classifiers. They can say this is in the picture looks more like a dog or more like a pigeon and sort of. But how about if you make neural network classify a Go board or a move into good or bad? Bingo!
Alpha-Go uses 3 networks:
- The policy network
- The value network
- The fast rollout network
The policy network looks for the current best moves in a board. But neural networks require a lot of processing and can be slow so it was reduced in a way it fails a little more but takes less time to evaluate. The value network predicts the winner player based on current board. So it is used to make a double check on those moves selected by the policy network in order to improove on the previous simplification.
And lately the fast rollout network (this is a small but fast network) picks the moves to feed the monte carlo tree search algorithm. So instead of picking random moves it is fed with random smart moves. And that running in a cluster of computers with CPUs and GPUs performing the search defeated professional players. Machine learning in essence combined with Monte Carlo tree search.
Of course those neural networks are not that easy to obtain. They require a lot of processing therefore computing power for the reinforcment learning. Self playing and evaluation of preexisting data. Actual human Go games. And there it is, half a century of artificial intelligence research.
You wight be wondering. What does this has to do with trading and why do we care? Well the big question is… If computers can defeat a champion Chess player or a champion Go player wouldn’t they be able to outerperform top traders? Actually the big question I think is… When? The technology developed with deep blue has being used to evaluating risk and trends in trading for instance. Another option is the optimization of trading portfolios that is constantly under heavy research even with quantum computers.
If you are interested details of the implementation of AlphaGo here is the link to the article in Nature Magazine
http://www.nature.com/nature/journal/v529/n7587/full/nature16961.html
And if you are interested in artificial inteligence and trading, I invite you to our forum where we can talk, discuss and learn about it.