Recientemente apareció en las noticias que el campeón de Go Lee Sedol fue derrotado por una IA (Inteligencia Artificial). Esto fue chocante pues los expertos predecían que lograr que una computadora jugara Go al nivel actual de Ajedrez no ocurriría antes de 10-15 años.
¿Como lo hicieron y por que se suponía que era un problema tan difícil? Usaron un truco interesante. La tecnología actual de una forma no convencional.
Pero primero hablemos de complejidad. Empecemos con el tic-tac-toe (o crucecitas y ceros). En teoría de juegos se pueden representar todas las posibles estrategias de un jugador en una forma llamada forma extensiva. Esto puede ser en un árbol. En este juego ambos jugadores toman turnos al igual que en Go y en Ajedrez. Así que con cada movimiento se puede crear un árbol donde todos los tableros están representandos por nodos y los vértices son las jugadas. Así que si hacemos que la computadora tome los caminos que terminan en victoria esta termina ganando o empatando.
Para tic-tac-toe el numero de tableros posibles es relativamente pequeño. Tiene solo 9 movimientos asi que el arbol es de 9 niveles. Y eliminando las simetrías el juego tiene 138 finales posibles. Esto es muy fácil de representar por una computadora, incluso los microcontroladores pueden jugar este juego. Este es un juego conocido como perfectamente resuelto. Nunca alguien puede ganarle a una computadora y a lo sumo solo se puede obtener un empate.

Esto se hace con un algortimo llamado minimax. El teorema principal que rige este algoritmo fue declarado por el matemático francés Émile Borel y se aplica en teoría de juegos a los juegos de suma cero. Exactamente es el mayor valor que el jugador está seguro de obtener sin conocer las acciones de otros jugadores. O dicho de otra forma, el menor valor que otros jugadores pueden forzar al jugador cuando conocen sus movimientos. Si quiere conocer mas detalles pueden dirijirse al artículo.
Para minimax se necesitan 3 cosas:
- Una forma de generar los tableros en cada movimiento
- Una forma de evaluar los tableros generados
- Escoger el mejor movimiento
Bien saltemos al Ajedrez. Este es un juego con un tablero mas grande, o sea representar cada tablero consume mas memoria que tic-tac-toe. Existen trucos para reducir este consumo pero aun así ocupa mas espacio. Pero entonces cada posible movimiento en Ajedrez comienza en 20. Y el juego promedio es de 40-50 movimientos. La cantidad de tableros llega a ser tan grande que no existe computadora que sea capaz de representar todas las posibles combinaciones. Y no ya pensar en calcularlos.
No es de mucho valor este método que luce como una fuerza bruta. Así que ¿Como las computadoras pueden derrotar a jugadores humanos? Bueno la cuestión es que no se necesita conocer todos los tableros para eso. Solo se necesita evaluar pasos hacia adelante suficientes tomando las mejores jugadas y olvidarse de los tableros donde las cosas empiezan a verse mal. Esto se conoce como prunning (en ingles podar). O sea podar el árbol de juegos.
¿Que es esto? Bueno esta basado en la idea de que cuando un juego empieza a verse mal ya no tiene sentido seguir jugando pues las cosas difícilmente mejoren. Así que esa es una mala jugada y se puede abandonar. Y como las malas jugadas son las mas comunes pues esto efectivamente reduce enormemente el tiempo de procesamiento y el consumo de memoria. La computadora solo emplea su tiempo en las jugadas que lucen mejor. Que pasa que el prunning trae un problema asociado. Y es que puede potencialmente descartar una jugada buena que empezó a lucir mal pero que a largo plazo era buena. Esto se conoce como el problema del horizonte. Para lidiar con este problema se emplea un algoritmo que se conoce como prunning alfa-beta. A pesar de ser muy interesantes sus variaciones y optimizaciones no entraremos en detalles. Solo dejaremos el enlace. Así que con mas de 18 jugadas hacia adelante, hardware especializado en ajedrez (chips que generan tableros) y muchos procesadores (CPUs) la supercomputadora Deep Blue venció en 1997 al campeon de ajedrez de entonces. Entonces usaba minimax pero los programas modernos usan prunning.
Bien ¿Cual es el problema con el Go? ¿No se puede utilizar lo anterior? El Go es un juego muy sencillo de jugar con reglas muy simples. En un tablero de 19×19 con piedras blancas y negras los jugadores toman turnos para capturar areas. Pero… no se dejen engañar por su simplicidad. Es un juego todavía mas complejo para las computadoras que el Ajedrez. ¿Por qué?
Tres razones:
- El numero de jugadas posibles promedio del Go son 250
- Cada juego tiene un promedio de 300 jugadas
- No es fácil decidir cuan bueno o malo es un tablero para un jugador (los campeones no pueden describir exactamente por que hacen las jugadas)
¿Como solucionar esto? Siempre se puede usar algo llamado Método de busqueda de árbol Monte Carlo. El método de Monte Carlo se usa a veces cuando algo no se sabe como evaluar o es muy complejo de calcular. Por ejemplo se usa par calcular algunas integrales muy complejas. Monte Carlo es un juego de experimentos probabilísticos basados en aleatoriedad y estadística. Y la búsqueda por Monte Carlo es una búsqueda probabilista que converge a minimax si se toman suficientes muestras (suficiente en este caso es alto, se puede asumir infinito).
¿Como funciona? Básicamente se toma un tablero, se escogen unos movimientos de forma aleatoria y simplemente se juega con esas jugadas a ver con cuantas se pierde o se gana. Y eso da una idea de cuan bueno o malo es un tablero. Mientras mas evaluaciones de movimientos mas se acerca a minimax. Así que esto permite escoger cuan cerca o lejos de este algoritmo se quiere. ¿Ya se lleva una idea de hacia donde va esto? No solo es la cantidad de tableros a evaluar, si no la complejidad de evaluar el tablero. Esto no sirve, al menos no para vencer a un jugador de Go profesional.
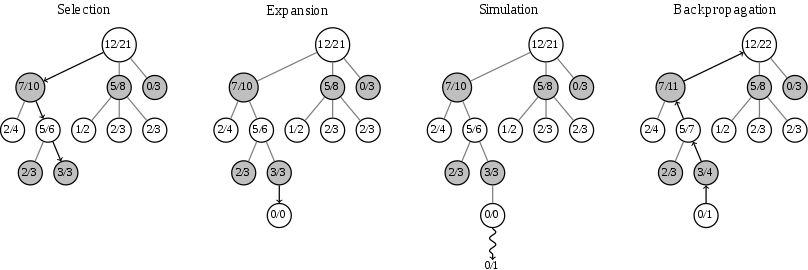
¿Entonces como los ingenieros de Deepmind lo resolvieron en Alpha-Go? Redes Neuronales. O una simulación por computadoras de una red neuronal biológica para ser mas precisos. Del tipo profunda. Ya las redes neuronales tienen bastante tiempo y están a nuestro alrededor por todos lados. Pero usarlas para esto fue la novedad.
¿Como las usaron acá? Bueno las redes neuronales pueden actuar como clasificadores. Pueden por ejemplo a partir de una fotografía con el suficiente entrenamiento decir esto se parece mas a un perro o a una paloma y así. Pero.. ¿que tal si se usa una red neuronal para clasificar un juego de Go o una jugada en buena o mala? Bingo!
Alpha-Go usa 3 redes:
- la red de políticas
- la red de valores
- la red de despliegue rápido
La red de políticas decide si un movimiento en un tablero es bueno o sea detecta los movimientos buenos. Pero las redes neuronales pueden ser grandes y requerir muchos cálculos así que pueden ser lentas. De modo que esta red fue reducida de forma que clasificara con menos exactitud pero fuera mucho mas rápida. Luego de este paso la red de valores predice cual jugador ganará con observar un tablero. De esta forma se hace un doble chequeo a la salida de la red de políticas de forma que en conjunto sea muy efectivo pero requiera mucho menos procesamiento.
Y al final la red de despliegue rápido selecciona los movimientos para alimentar al algoritmo de búsqueda de árbol por Monte Carlo. De forma que en vez de seleccionar movimientos aleatorios este selecciona movimientos aleatorios inteligentes. Esto ejecutándose en un cluster de computadoras con GPUs (o TPUs de Tensor Processing Unit) venció a los campeones de Go.
Claro esas redes neuronales no son fáciles de obtener. Requiren mucho procesamiento para el aprendizaje reforzado. Simulación de juegos contra sí misma y evaluación de datos preexistentes. Juegos de Go reales. Y a eso llegan 50 años de investigación en inteligencia artificial.
Quiza se esté preguntando. ¿Que tiene esto que ver con Trading y por que nos interesa? Bueno la pregunta es… ¿Si las computadoras pueden derrotar a un campeón de Ajedrez o de Go no serán capaces de sobrepasar a los Traders de mas rendimiento? Creo que la buena pregunta realmente es… ¿Cuando? La tecnología que se desarrolló con Deep Blue se ha usado para evaluación de tendencias y riesgos de mercado por ejemplo. En cualquier caso es interesante conocer los detalles de desarrollo en inteligencia artificial. Y claro esta el manejo de portafolios de trading es un area todavía en fuerte estudio donde incluso se estan empezando a usar computadoras cuánticas.
Si tienen interés en conocer los detalles de la implementación de Alpha-Go aca les dejo el enlace a la Revista Nature (en inglés)
http://www.nature.com/nature/journal/v529/n7587/full/nature16961.html
Y si tienes interés en la inteligencia artificial y el trading, te invito a unirte a nuestro foro donde podemos hablar, discutir y aprender sobre el tema.